GOSIM 2026

 Workstation Heterogeneous Inference for Frontier MoE Models
Workstation Heterogeneous Inference for Frontier MoE Models
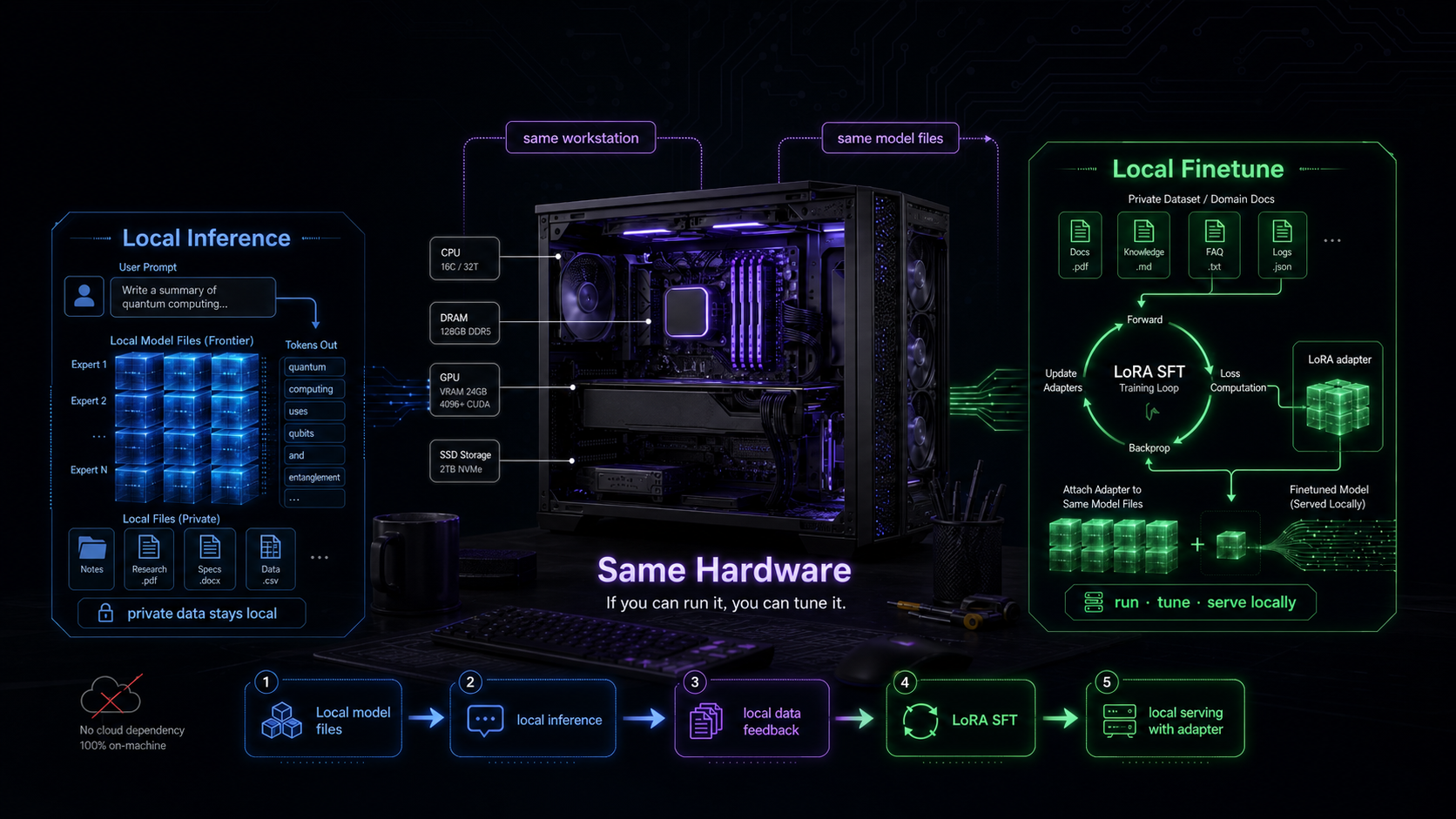
From Local Inference to Local Finetune
Three Inference Regimes
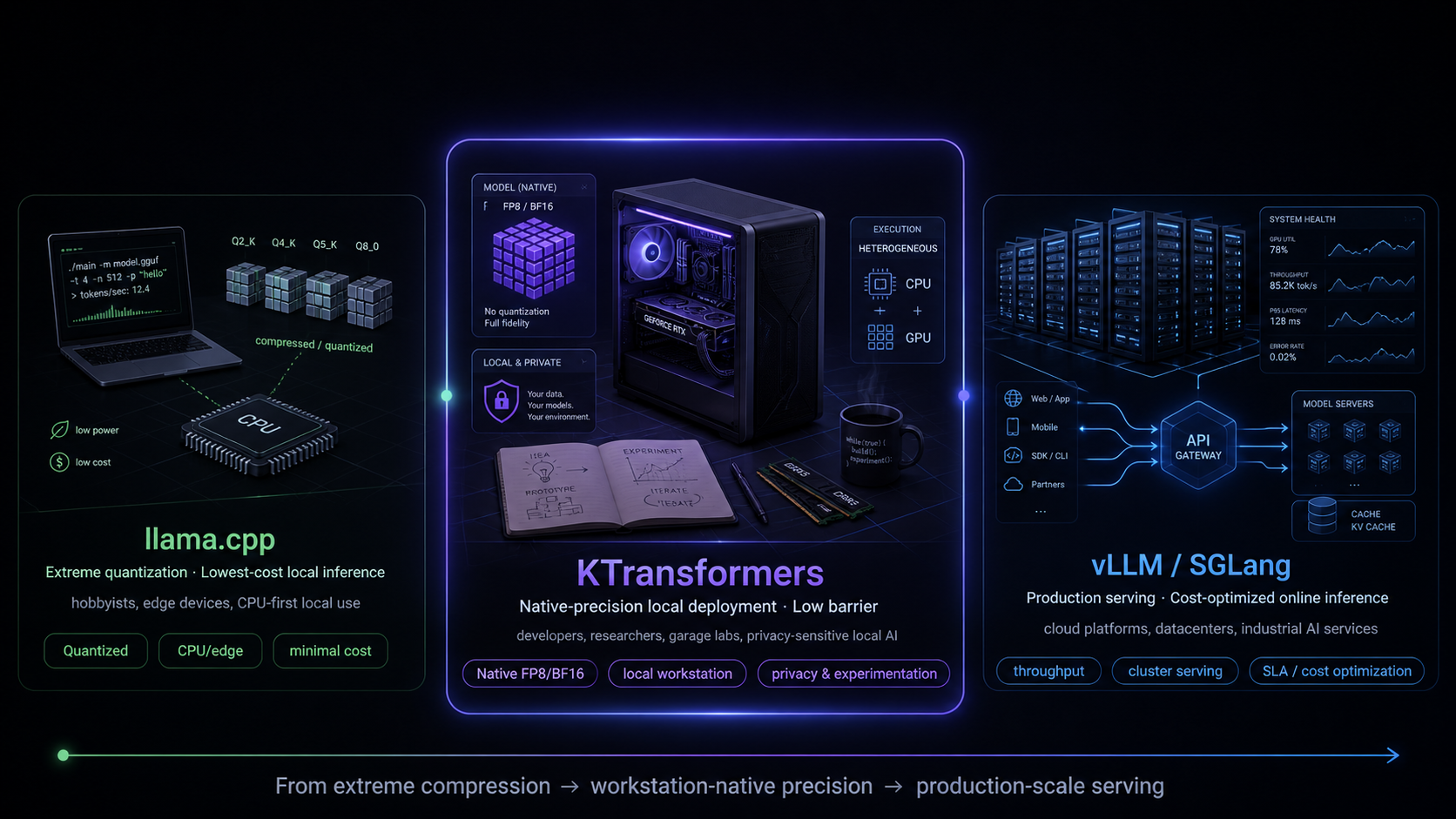
Key Idea
The Model Is Already Heterogeneous
Attention, KV cache, shared experts, routed experts, prefill, and decode do not want the same hardware behavior.
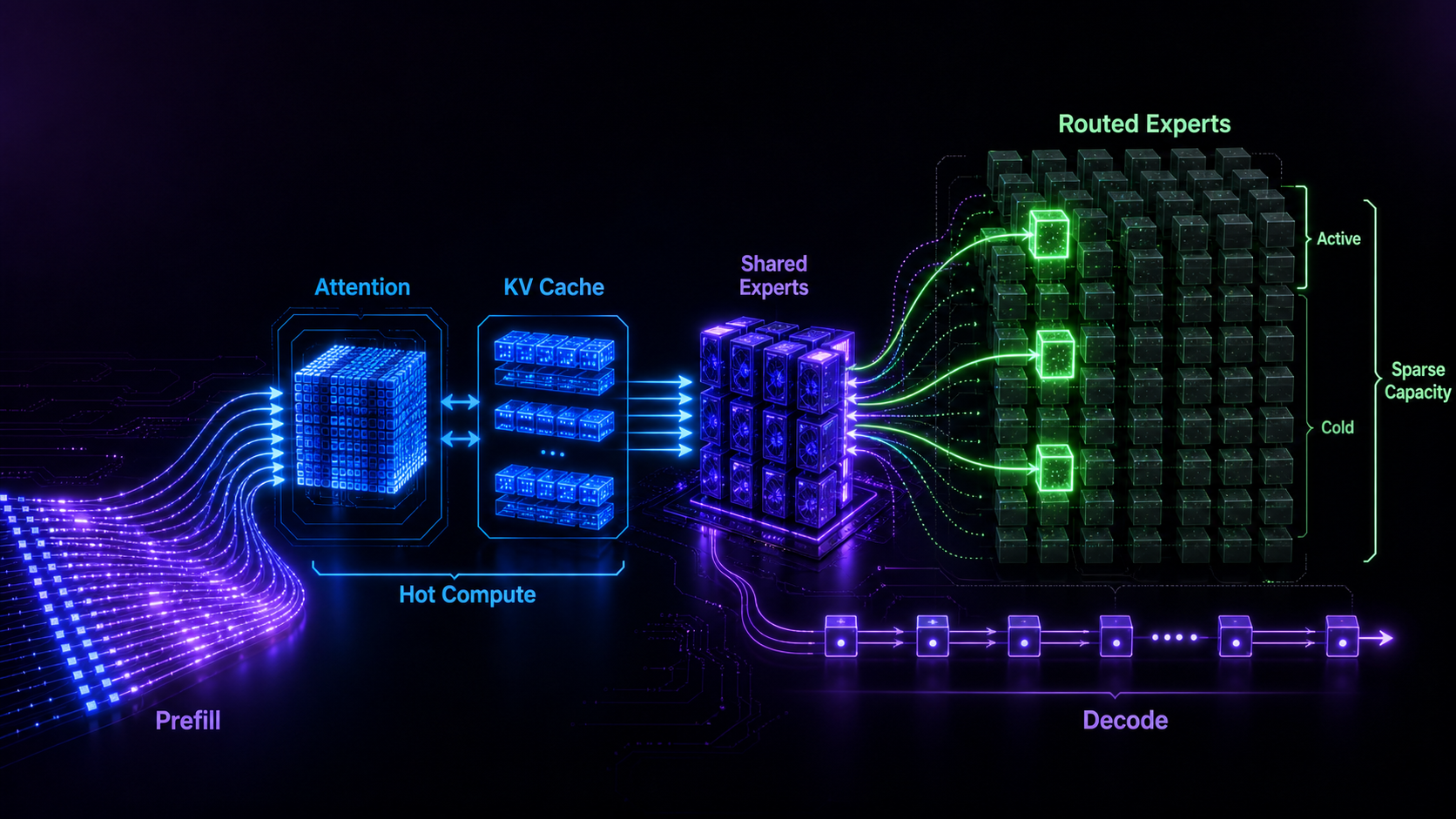
Architecture
Map Work to the Right Device
Split the model by arithmetic intensity, not by a simple "GPU full, CPU fallback" rule.

One Workstation,
Two Resources

Architecture
NUMA-aware Tensor Parallel
Once CPU memory becomes part of the inference system, memory locality matters as much as kernel speed.
KTransformers: place expert weight slices in the local memory of each NUMA node.
- Memory access stays local to each NUMA node
- Avoids expensive cross-NUMA traffic
- Uses AMX / VNNI / AVX paths for CPU expert compute
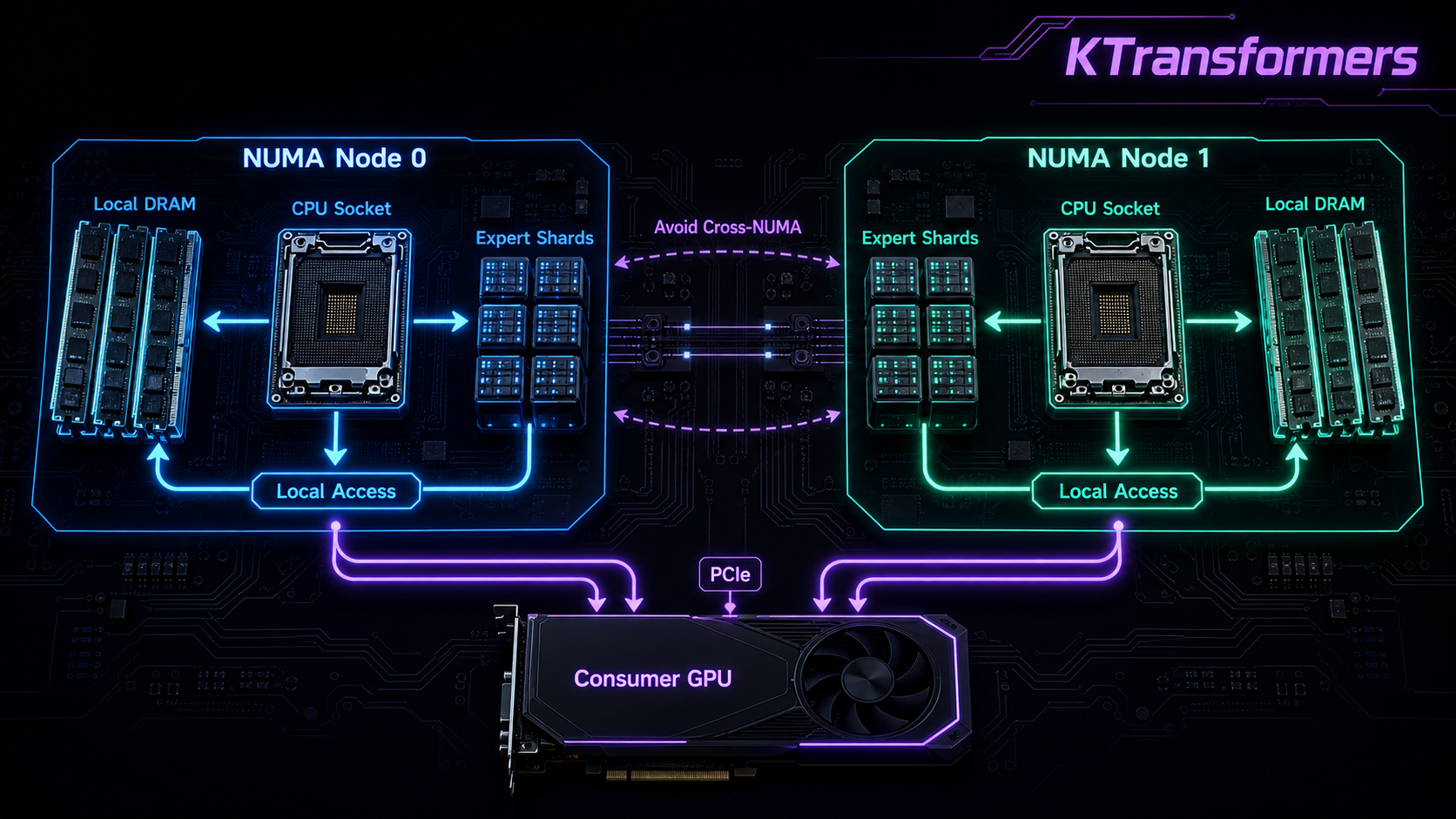
Architecture
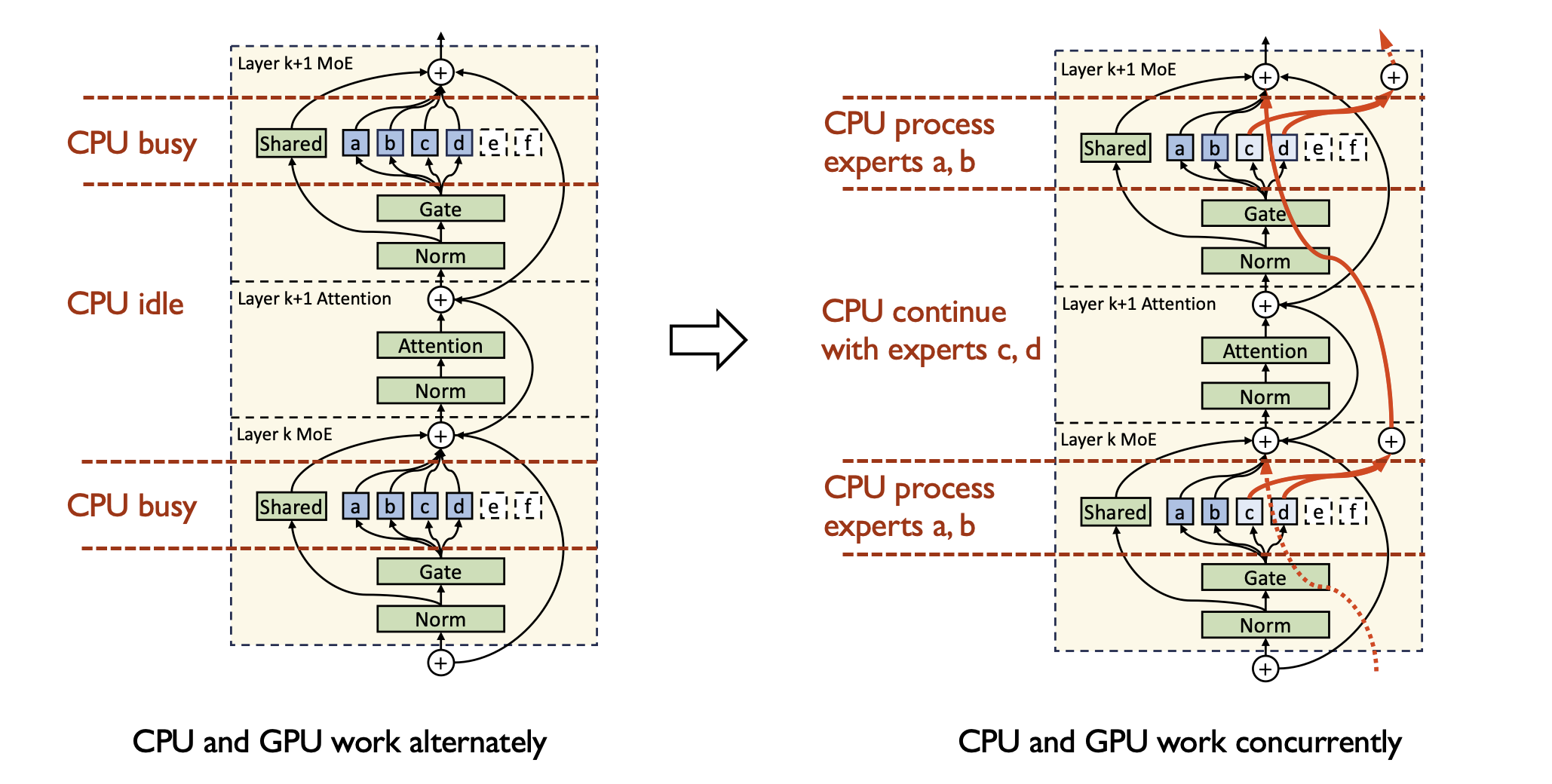
Expert Deferral
The hard part is not putting experts on CPU. The hard part is keeping CPU and GPU busy at the same time.
Expert Deferral: defer non-critical experts so attention and expert compute overlap across layers.
- CPU processes routed experts while GPU runs attention
- GPU moves ahead instead of waiting for every expert immediately
- Overlap turns heterogeneous hardware into one pipeline
Long Context
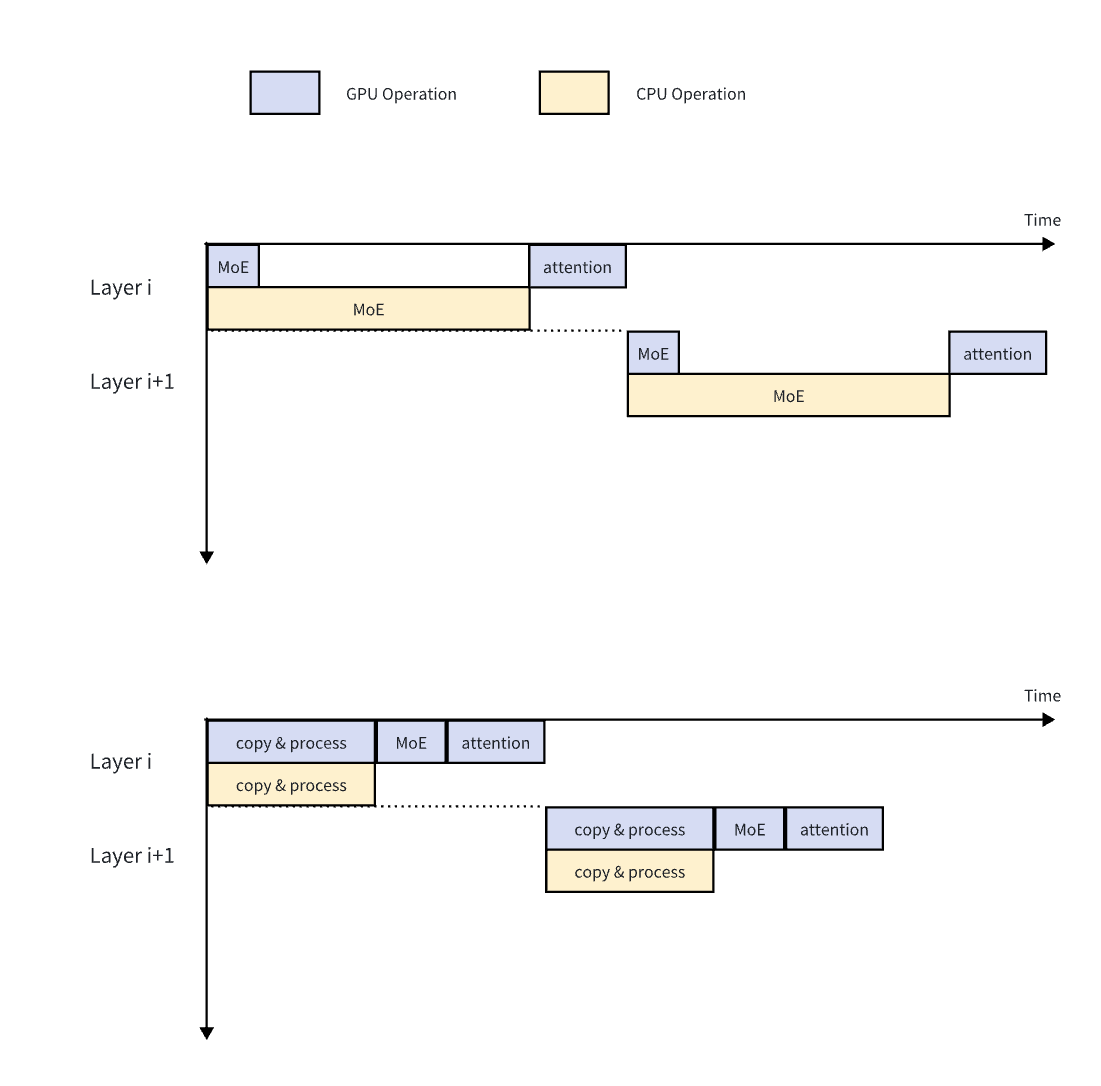
Layer-wise Prefill
Prefill is a different workload from decode. For 16K–64K contexts, CPU expert compute can become the bottleneck.
Layer-wise Prefill: transfer weights layer by layer to GPU, then use optimized GPU kernels for the long-context burst.
- Multi-CUDA-stream overlap saturates PCIe 5.0 bandwidth
- CPU and GPU formats are converted on the fly, with one stored copy
- 7–9× speedup at 16K–64K context
Optimization
Dynamic Expert Placement
Not all experts are equally hot. Expert activation shows stable hot/cold patterns inside a session.
Dynamic update: observe actual activations during prefill and adjust GPU expert placement on the fly.
- Hot experts stay close to GPU compute
- Cold experts remain in CPU memory
- 10–30% decode speedup from better placement
Capability
Expanding the Workstation Sweet Spot
KTransformers features are not random additions. They expand the same heterogeneous workstation lane.

Results
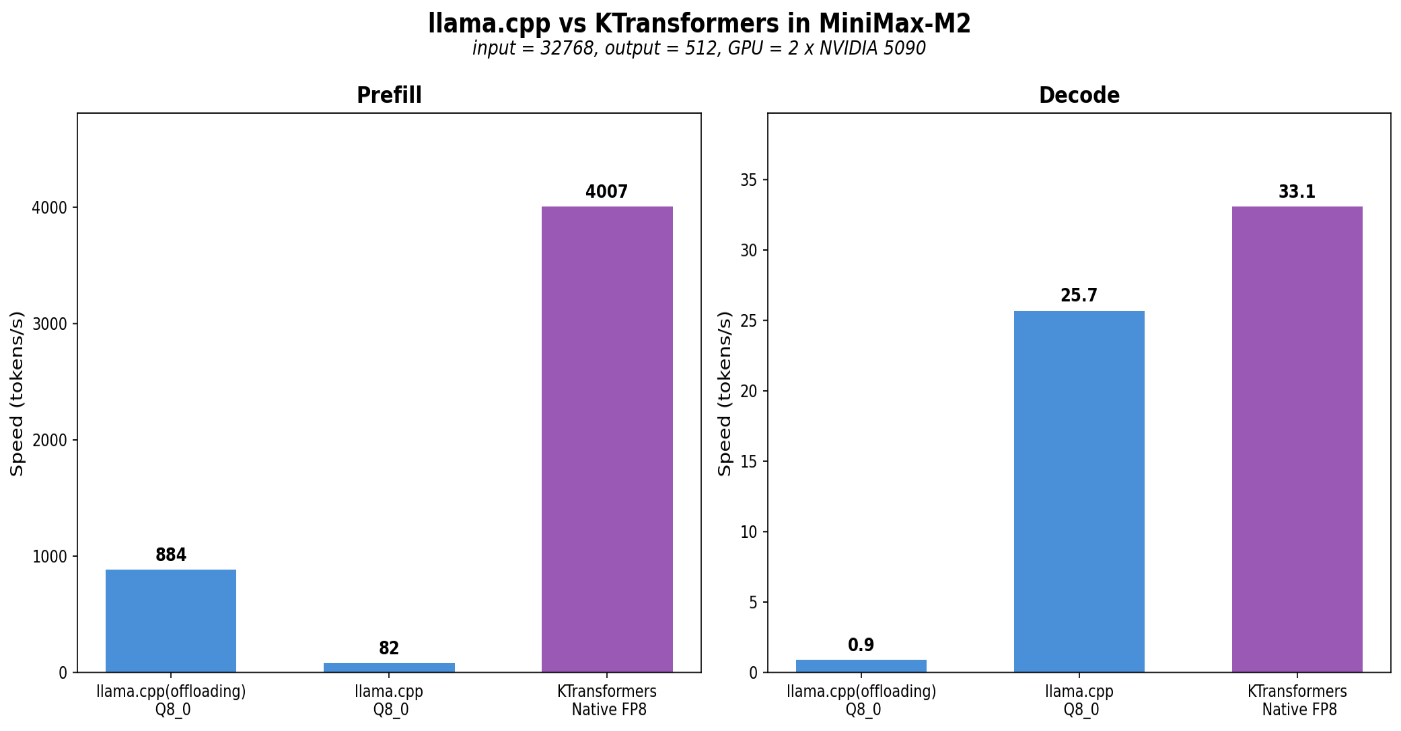
Performance in the Workstation Lane
vs llama.cpp on the same hardware
- FP8 native precision, no int4 compromise
- Long-context prefill: 7–9× faster at 16K–64K
- The point is not pure CPU or pure GPU. The point is the workstation as a system.
Ecosystem
Officially Recommended
Leading open-source model teams recommend KTransformers in their official READMEs and deployment guides.
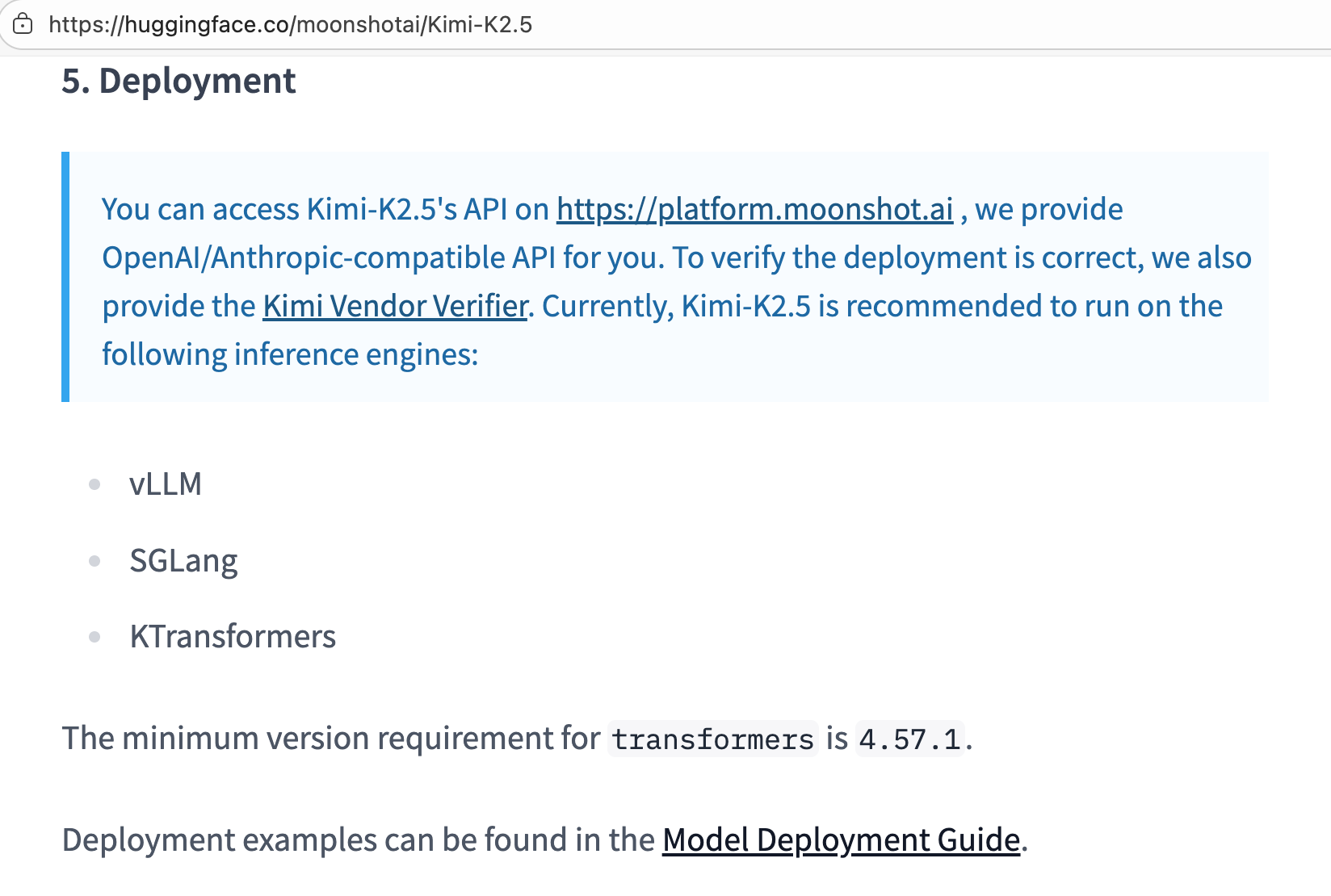

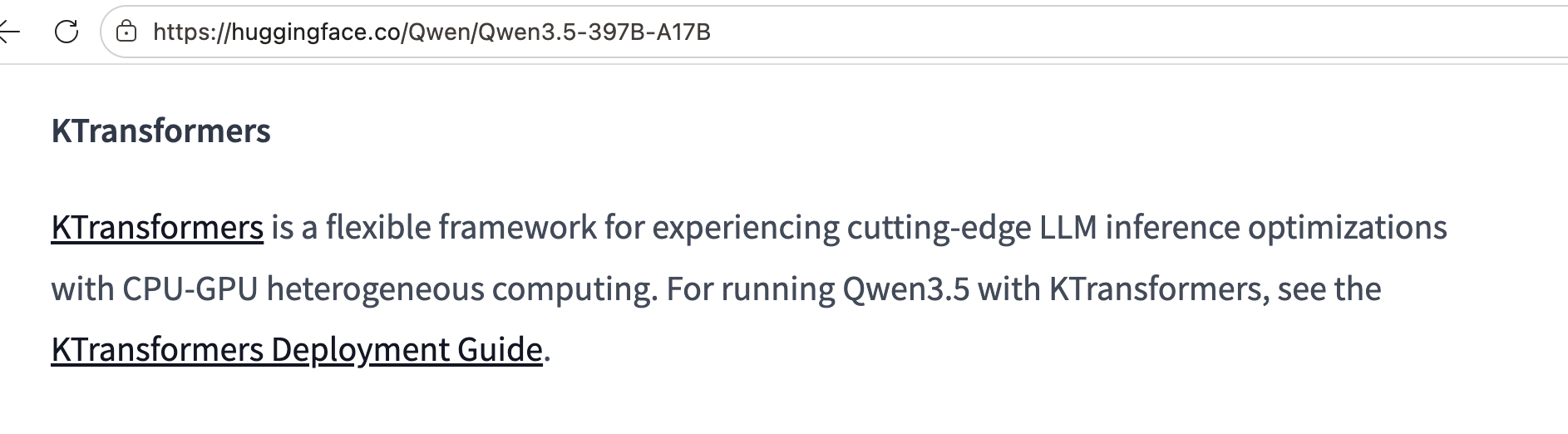
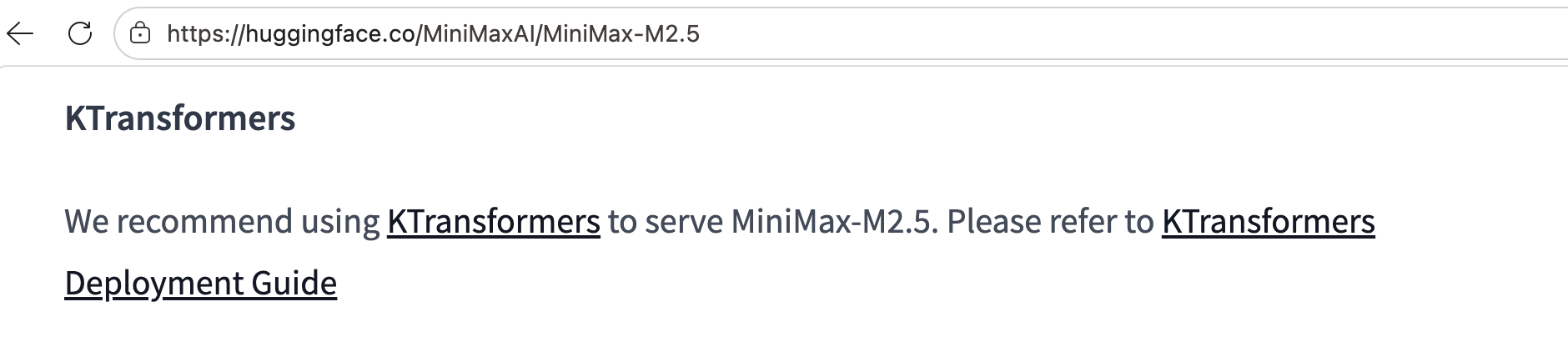
Ecosystem
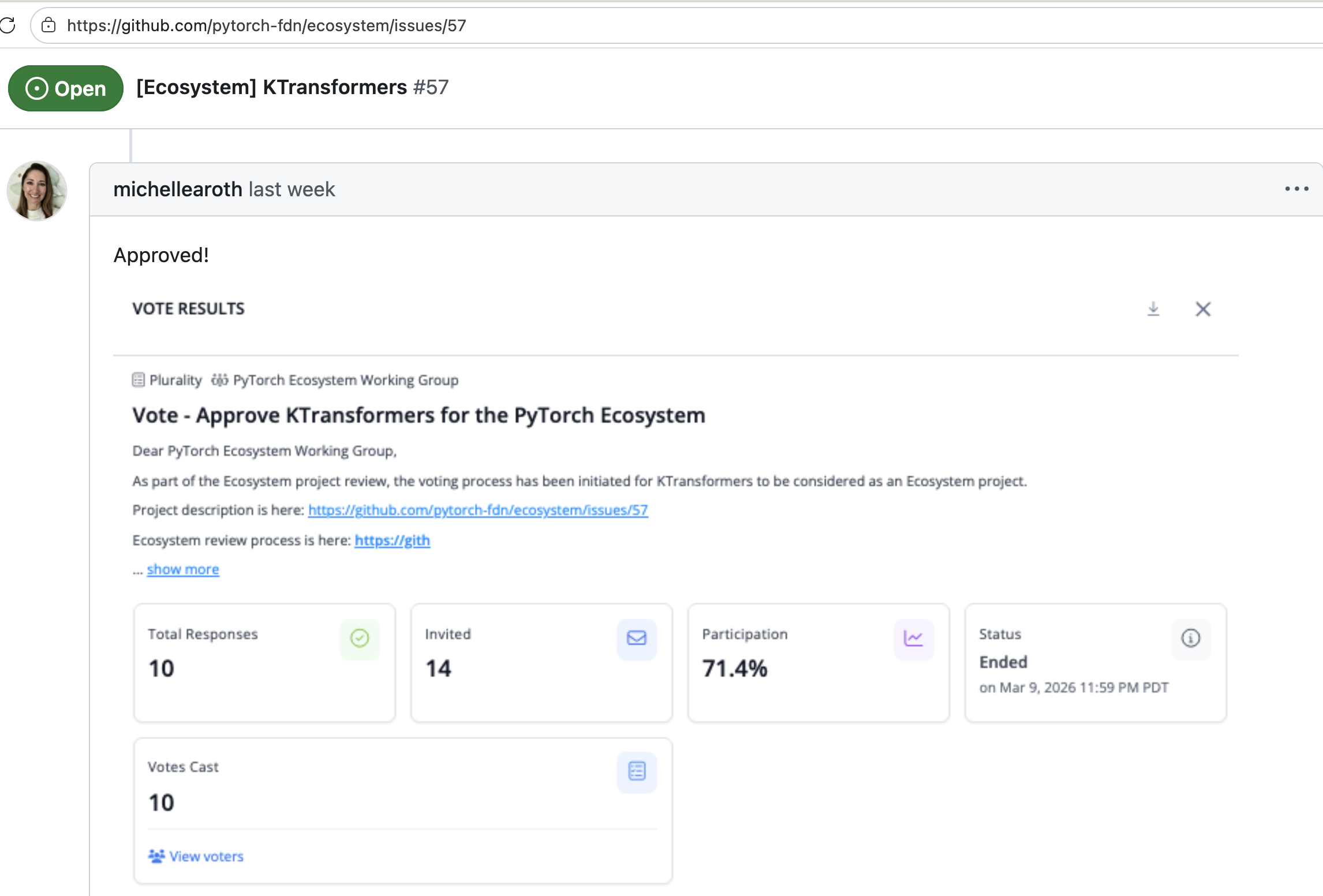
Joined PyTorch Ecosystem
KTransformers was accepted into the PyTorch official ecosystem, bringing heterogeneous inference into the mainstream AI infrastructure conversation.
- Recognized for advancing CPU-GPU heterogeneous execution
- Built around PyTorch-native tensor workflows
- Aligned with serving stacks such as SGLang and HF Transformers
Community
Website & Leaderboard
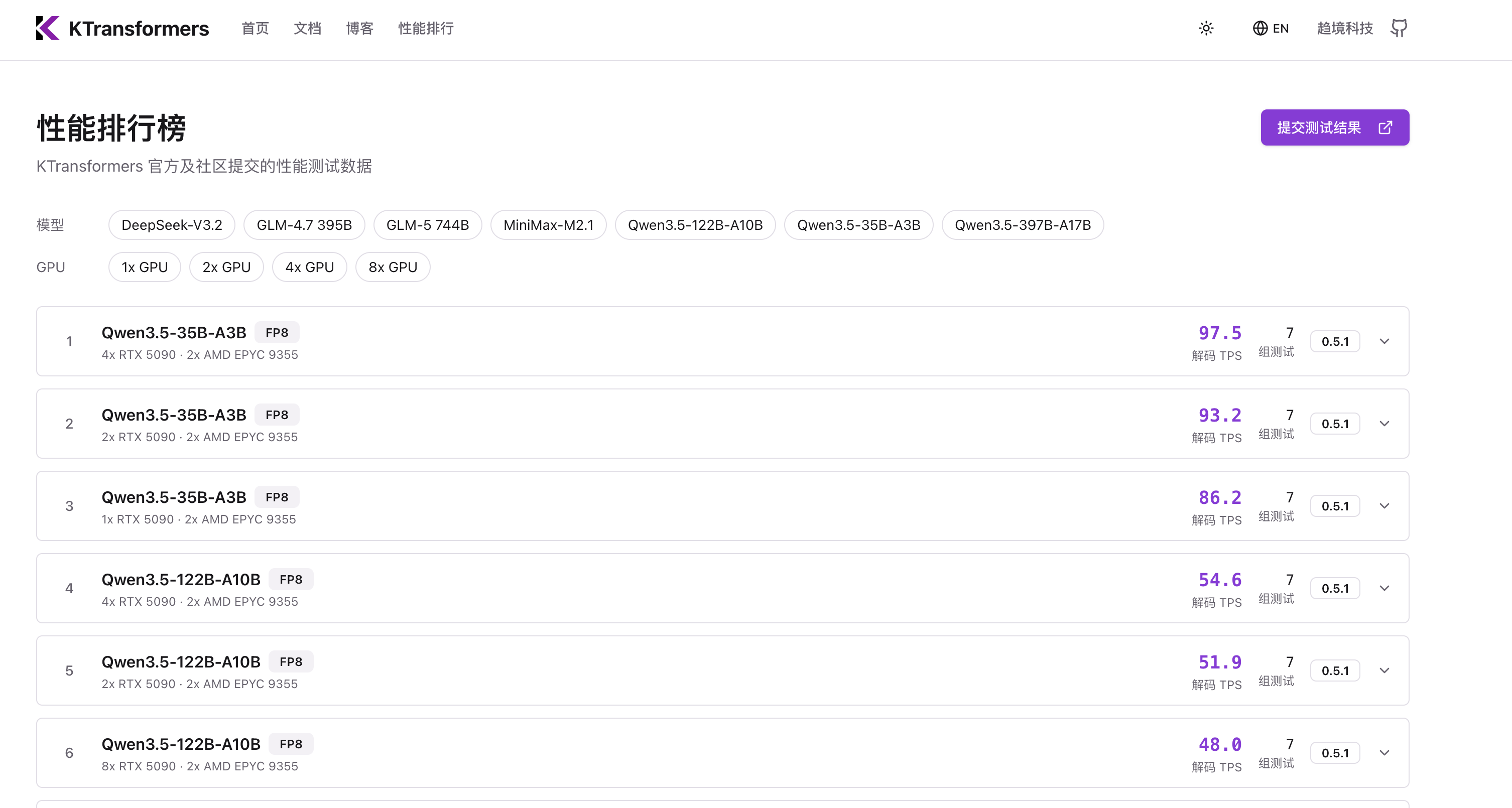
Community-driven benchmarks at kvcache.ai: submit hardware configurations, compare results, and reproduce the workstation lane.
Local Inference
to Local Finetune